| Home |
| General |
| Contact Us |
| PDL/81 |
| Compilers |
PDL - A Tool for Software Design
PDL/81 — a tool for software design
The Original PDL Paper
by Stephen H. Caine and E. Kent Gordon
Caine, Farber & Gordon, Inc.
Pasadena, California©1975 American Federation of Information Processing Societies. Reprinted by permission.
This paper was originally published in the Proceedings of the 1975 National Computing Conference which was held in Anaheim, California. It has since been republished in many collections on the theory and practice of software design.
As you read the paper and wonder why so many seemingly-obvious points are being made and examples being shown, remember that it was written in late 1974 and early 1975 at a time when concepts such as structured programming and nested IF statements were considered new and daring.
Table of Contents
- Introduction
- Purpose of PDL
- Designing for People in PDL
- Form of a Design in PDL
- Design Constructs
- Future Directions
- Conclusions
- References
- Tables
- Figures
Introduction
During the past several years [pre-1975], industry has seen an explosion in the cost of software production coupled with a decline in the quality and reliability of the results. A realization that structured programming, top-down design, and other changes in techniques can help has alerted the field to the importance of applying advanced design and programming methods to software production[1,2].For the past four years, Caine, Farber & Gordon, Inc. has used such advanced techniques as structured programming, top-down design and system implementation, centralized program production libraries, and egoless programming teams for all of its programming. With these techniques we have achieved a level of productivity comparable to that recently reported by others employing similar techniques[3-8].
However, within the last year, we greatly refined these techniques, applying them to design as well as to programming. This has resulted in increases productivity, greatly decreased debugging effort, and clearly superior products. On recent complex projects we have achieved production rates, over the full development cycle, of 60-65 lines of finished code per man-day and computer utilization of less than 0.25 CPU hours per thousand lines of finished code. For comparison, these production rates are approximately half again better than our best efforts using just structured programming techniques and 4-6 times better than average industrial experience using classical techniques. Computer usage was four times smaller than our experience with just structured programming techniques and more than 10 times smaller than classical industrial averages.
As an example, consider the two CFG projects shown in Table 1. Project “A” is a major component of a seismic data processing system for oil exploration. It was produced using classical structured programming techniques and production rates compare favorably to other projects[3] which used similar techniques. Project “B” is a system for the automatic restructuring of Fortran programs[9]. It was developed using the latest CFG methods. Production rates were 50 percent better than for Project “A” and the amount of computer time used in development was approximately one quarter of that used for the first project. In each case, a line of code was taken to be one 80-column source card with common data definitions counted only once. Both projects were developed using an IBM 370/158.
In order to achieve the results that we are currently experiencing, we have developed a comprehensive software production methodology which places its greatest emphasis on design. Before any code is written, a complete design is produced which contains:
The design is produced and presented top-down and is oriented toward understandability by people. While in no sense is our design process automated, it is supported by a series of tools—the Program Design Language (PDL) and its computerized processor. Both of these have been in extensive use since the autumn of 1973.
- all external and internal interface definitions
- definitions of all error situations
- identification of all procedures
- identification of all procedure calls
- definition of all global data
- definition of all control blocks
- specification of the processing algorithms of all procedures
The Purpose of PDL
PDL is designed for the production of structured designs in a top-down manner. It is a pidgin language in that it uses the vocabulary of one language (i.e. English) and the overall syntax of another (i.e., a structured programming language). In a sense, it can be thought of as structured English.While the use of pidgin languages is also advocated by others, we have taken the additional steps of imposing a degree of formalism on the language and supplying a processor for it. Input to the processor consists of control information plus designs for procedures (called segments in PDL). The output is a working design document which can, if desired, be photo-reduced and included in a project development workbook.
The output of the processor completely replaces flowcharts since PDL designs are easier to produce, easier to change, and easier to read than are designs presented in flowchart form.
Designing for People in PDL
Like a flowchart, and unlike a program, PDL can be written with whatever level of detail is appropriate to the problem at hand. A designer can start with a few pages giving the general structure of his system and finish, if necessary, with even more precision than would exist in the corresponding program.In our experience, the purpose of a design is to communicate the designer's idea to other people—not to a computer. Figure 1 shows a sample design segment for a simple exchange sort. Note that we are not attempting to illustrate efficient sorting methods. Rather, having decided to use this particular sorting method, we wish to present the algorithm in such a way that it can be easily comprehended. Given that the DO UNTIL construct represents a loop whose completion test occurs at the end of the loop, the operation of the algorithm is apparent. It is clearly better, from the viewpoint of understandability, than either the flowchart of Figure 2 or the translation of the algorithm into PL/I as shown in Figure 3.
A virtue of PDL is that a rough outline of an entire problem solution can be quickly constructed. This level of design can be easily understood by people other than the designer. Thus, criticisms, suggestions, and modifications can be quickly incorporated into the design, possibly resulting in complete rewrites of major sections. When the design has stabilized at this level, more detail can be added in successive passes through the design with decisions at each point affecting smaller and smaller areas.
The Form of a Design in PDL
A design produced in PDL consists of a number of flow segments, each corresponding roughly to a procedure in the final implementation. A sample of a high-level flow segment from a large design is shown in Figure 4. If a statement in a segment references another flow segment, the page number of the referenced segment is shown to the left of the referencing statement. A sample low-level segment is shown if Figure 5.The statements which compose a flow segment are entered in free form. The PDL processor automatically underlines keywords, indents statements to correspond to structure nesting levels, and provides automatic continuation from line to line.
Design information may also be entered in text segments. These contain purely textual information such as commentary, data formats, assumptions, and constraints.
The document output by the PDL processor is in a form ready for photo-reduction and publication. It contains:
- a cover page giving the design title, date, and processor identification
- a table of contents (Figure 6)
- the body of the design, consisting of flow segments and text segments
- a reference tree showing how segments references are nested (Figure 7)
- a cross-reference listing showing the page and line number at which each segment is referenced (Figure 8)
Design Constructs
What goes into a design segment is generally at the discretion of the designer. In choosing the form of presentation, he is guided by a compendium of style which has been developed through extensive experience. However, the language and the processor have been defined to encourage and support design constructs which relate directly to the constructs of structured coding. The two primary constructs are the IF and the DO.The IF construct
The IF construct provides the means for indicating conditional execution. It corresponds to the classical IF...THEN...ELSE construct of Algol-60[10] and PL/I, augmented by the ELSEIF of languages such as Algol-68[11]. The latter is used to prevent excessive indentation levels when cascaded tests are used.The General form of the construct is shown in Figure 9. Any number (including zero) ELSEIF's are allowed and at most one ELSE is allowed.
The DO Construct
This construct is used to indicate repeated execution and for case selection. The reasons for the dual use of this construct are historic in nature and closely map several of the in-house implementation languages we frequently use. It may be effectively argued that a separate construct for case selection would be better.The iterative DO is indicated by:
DO iteration criteria one or more statements ENDDOThe iteration criteria can be chosen to suit the problem. As always, bias toward human understandability is preferred. Statements such as:DO WHILE THERE ARE INPUT RECORDS DO UNTIL "END" STATEMENT HAS BEEN PROCESSED DO FOR EACH ITEM IN THE LIST EXCEPT THE LAST ONEoccur frequently in actual designs.Our experience, and that of others[7], has shown that a provision for premature exit from a loop and premature repetition of a loop are frequently useful. To accomplish this we take the statement
UNDOto mean that control is passed to the point following the ENDDO of the loop. Likewise,CYCLEis taken to mean that control is to pass to the loop termination testSince we may wish that an UNDO or CYCLE apply to an outer loop in a nest of loops, any DO may be labeled and the label may be placed after the UNDO or CYCLE.
Case selection is indicated by
DO CASE selection criteriaAgain, we advocate the use of understandable selection criteria such asDO CASE OF TRANSACTION TYPE DO CASE OPERATOR TYPE DO CASE OF CONTROL CARD VERBGenerally, we use labels in the body of the DO to indicate where control passes for each case. This is illustrated in Figure 10.Future Directions
The results we have achieved with PDL have exceeded our original expectations. However, it is clear that further development is both possible and desirable. The areas which we are currently exploring include:
- handling of data: The current PDL presents a procedural design—a design of control flow and processing actions. It would be very desirable to have a similar mechanism for the design of data structures and data flow. A method for integrating the data and procedural designs and performing mutual cross-referencing would be very powerful, indeed.
- interactive versions: The current PDL processor is batch oriented. The ability to compose and, more importantly, to modify a design on-line in a manner specifically planned for interactive use would be of great assistance. This would be particularly advantageous during the early stages of a project when design changes are often frequent and extensive.
- total design system: An integrated computer system for software design, such as the DES system of Professor R. M. Graham[12], is a natural outgrowth of our work with PDL. Such a system would act as an information management system maintaining a data base of designs. Designs could be entered and modified; question about a design and the inter-relations of its parts could be asked and answered; reports on design status and completeness could be prepared. Provision for simulation of a design for performance estimation and a mechanism for translation from design to code are also important.
Conclusions
In the autumn of 1973, we integrated the use of PDL and its processor into our software design and implementation methodology. Since then, it has been used on a number of projects of varying sizes. The results have been comparable to those discussed earlier.PDL is not a panacea and it is certainly possible to produce bad designs using it. However, we have found that our designers and programmers quickly learn to use PDL effectively. Its emphasis on designing for people provides a high degree of confidence in the correctness of the design. In our experience, it is almost impossible to “wave your hands” in PDL. If a designer doesn't really yet see how to solve a particular problem, he can't just gloss over it without the resulting design gap being readily apparent to a reader of the design. This, plus the basic readability of a PDL design, means the clients, management, and the team members can both understand the proposed solution and gauge its degree of completeness.
We have also found that PDL works equally well for large and small projects. Because it is so easy to use, persons starting to work on even a “quick and dirty” utility will first sketch out a solution in PDL. In the past such programs were usually written with little or no design preceding the actual coding.
References
- Boehm, B. W., Software and its Impact: A Quantitative Assessment, Datamation, May 1973, pp. 48-59.
- Goldberg, J., (editor), Proceedings of a Symposium on the High Cost of Software, Stanford Research Institute, 1973.
- Baker, F. T., Chief Programmer Team Management of Production Programming, IBM Sys. J., Vol. 11, No. 1, 1972, pp. 56-73.
- Bohm, C. and G, Jacopini, Flow Diagrams, Turing Machines and Languages With Only Two Formation Rules, Comm. ACM, May 1966, pp. 366-371.
- Dijkstra, E., GO TO Statements Considered Harmful, Comm. ACM, March 1968, pp. 147-148.
- Mills, Harlan D., On the Development of Large Reliable Programs, IEEE Symp. Computer Software Reliability, 1973, pp. 155-159.
- Peterson, W. W., T. Kasami and N. Tokura, On the Capabilities of WHILE, REPEAT, and EXIT Statements, Comm. ACM, August 1973, pp. 503-512.
- Stevens, W. P., G. J. Myers and L. L. Constantine, Structured Design, IBM Sys. J., Vol. 13, No. 2, 1974, pp. 115-139.
- De Balbine, G., Better Manpower Utilization Through Structured Programming, Caine, Farber & Gordon, Inc., 1974 (in publication).
- Naur, P. et. al., Report on the Algorithmic Language ALGOL 60, Comm. ACM, May 1960, pp. 299-314.
- Van Wijngaarden, A. et. al., Report on the Algorithmic Language ALGOL 68, Numerishe Mathematik, 14, 1969, pp. 79-218.
- Graham, R. M., G. J. Clancy and D. B. Devaney, A Software Design and Evaluation System, Comm. ACM, February 1973, pp. 110-116.
Tables
Table 1. Production Comparison Project A Project B Development Method Classical Structured Latest CFG Programming Language PL/I Dialect PL/I Size of Program (Lines) 32,000 27,000 Size of Team 3-6 3-5 Elapsed Time (Months) 9 6 Lines per Man-Day 40 65 CPU Hours per 1000 Lines (IBM 370/158) 0.90 0.16 Figures
Figure 1. PDL design of a simple sorting algorithmSORT (TABLE, SIZE OF TABLE) IF SIZE OF TABLE > 1 DO UNTIL NO ITEMS WERE INTERCHANGED DO FOR EACH PAIR OF ITEMS IN TABLE (1-2, 2-3, 3-4, ETC.) IF FIRST ITEM OF PAIR > SECOND ITEM OF PAIR INTERCHANGE THE TWO ITEMS ENDIF ENDDO ENDDO ENDIF
Figure 2. Flowchart for sorting algorithm of Figure 1
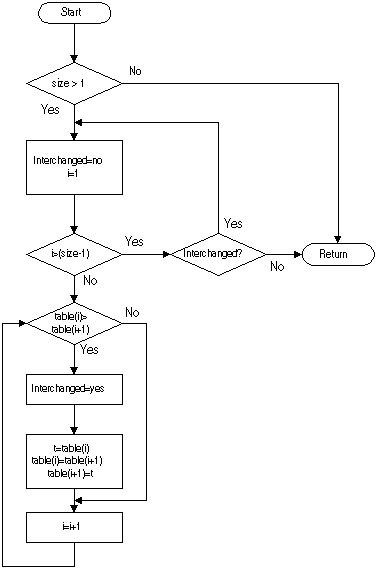
Figure 3. PL/I procedure for sorting algorithmSORT: PROCEDURE(TABLE); DECLARE TABLE(*) FIXED BIN; DECLARE INTERCHANGED BIT(1); DECLARE TEMP FIXED BIN; IF DIM(TABLE,1) > 1 THEN DO; INTERCHANGED='1'B; DO WHILE (INTERCHANGED); INTERCHANGED='0'B; DO I=LBOUND(TABLE,1) TO HBOUND(TABLE,1)-1; IF TABLE(I) > TABLE(I+1) THEN DO; INTERCHANGED='1'B; TEMP=TABLE(I); TABLE(I)=TABLE(I+1); TABLE(I+1)=TEMP; END; END; END; END; END SORT;
Figure 4. Sample of a high-level PDL flow segmentNote: In the original paper, the contents of this figure were set in upper-case with underscored keywords. Because many browsers do not support underscoring, we have reset it in lower-case with upper-case keywords.CFG, INC. AIL DEVELOPMENT WORKBOOK (14.90) 06 JUL 74 PAGE 39 EXPRESSION AND REFERENCE PROCESSING Process Expression Ref Page ******************************************************************************** * * * 1 push "soe" (start of expression) onto operator stack * 40 * 2 process operand * * 3 DO while next token is an operator * * 4 DO while operator is not same as operator on top of operator stack and/* * its precedence is less than or equal to precedence of/ * * operator on the top of the operator stack * 42 * 5 build top node * * 6 pop operator stack * * 7 ENDDO * * 8 IF new operator is same as top operator on operator stack * * 9 increment operand count in top of operator stack by one * * 10 ELSE * * 11 push new operator and operand count of 2 onto operator stack * * 12 ENDIF * 40 * 13 process operand * * 14 ENDDO * * 15 DO while top of operator stack is not "soe" * 42 * 16 build top node * * 17 pop operator stack * * 18 ENDDO * * 19 pop operator stack * * 20 (top of operand stack contains top node in expression) * * * ********************************************************************************
Figure 5. Sample low-level PDL flow segmentNote: In the original paper, the contents of this figure were set in upper-case with underscored keywords. Because many browsers do not support underscoring, we have reset it in lower-case with upper-case keywords.CFG, INC. LOCOMOTOR DATA REDUCTION 15 OCT 74 PAGE 21 DATA COMPRESSION AVERAGE OVER POINTS (RADIUS) Ref Page ******************************************************************************** * 1 IF debugging * 29 * 2 start line (current cycle) * 28 * 3 print points in buffer (current buffer) * * 4 ENDIF * * 5 points <- 0 * * 6 sx <- 0 * * 7 sy <- 0 * * 8 buffer <- previous of previous buffer * * 9 DO for 5 buffers * 22 * 10 move good points to work buffer (buffer,radius) * * 11 IF debugging * 28 * 12 print points in buffer (work buffer) * * 13 ENDIF * * 14 IF point count of work buffer > 0 * * 15 DO for points in work buffer * * 16 add x to sx * * 17 add y to sy * * 18 ENDDO * * 19 add point count of work buffer to points * * 20 ENDIF * * 21 buffer <- next buffer * * 22 ENDDO * * 23 IF points > 0 * * 24 ax <- sx/points * * 25 ay <- sy/points * * 26 ELSE (no data for point) * * 27 ax <- negative * * 28 ay <- 0 * * 29 ENDIF * * * ********************************************************************************
Figure 6. Sample table of contents from a PDL design
CFG, INC. AIL DEVELOPMENT WORKBOOK (14.90) TABLE OF CONTENTS TABLE 0F CONTENTS ----------------- INTRODUCTION . . . . . . . . . . . . . . . . . . . . . . . . 2 PURPOSE OF SECTION. . . . . . . . . . . . . . . . . . . . 3 DICTIONARY ALGORITHMS. . . . . . . . . . . . . . . . . . . . 4 FIND DICTIONARY ENTRY . . . . . . . . . . . . . . . . . . 5 SEARCH ONE BLOCK. . . . . . . . . . . . . . . . . . . . . 6 SEE IF MATCH. . . . . . . . . . . . . . . . . . . . . . . 7 TOKEN SCANNING . . . . . . . . . . . . . . . . . . . . . . . 8 BACK UP SCANNER . . . . . . . . . . . . . . . . . . . . . 9 SCAN ONE TOKEN. . . . . . . . . . . . . . . . . . . . . . 10 SKIP BLANKS . . . . . . . . . . . . . . . . . . . . . . . 11 SKIP COMMENT. . . . . . . . . . . . . . . . . . . . . . . 12 SCAN IDENTIFIER . . . . . . . . . . . . . . . . . . . . . 13 SCAN SPECIAL CHARACTER. . . . . . . . . . . . . . . . . . 14 GET NEXT CHARACTER. . . . . . . . . . . . . . . . . . . . 15 SOURCE INPUT . . . . . . . . . . . . . . . . . . . . . . . . 16 READ NEXT SOURCE CARD . . . . . . . . . . . . . . . . . . 17 LIST SOURCE CARD. . . . . . . . . . . . . . . . . . . . . 18 MAIN PROCESSING LOOP . . . . . . . . . . . . . . . . . . . . 19 MAIN LOOP . . . . . . . . . . . . . . . . . . . . . . . . 20 PROCESS ONE STATEMENT . . . . . . . . . . . . . . . . . . 21 SETUP STATEMENT . . . . . . . . . . . . . . . . . . . . . 22 VERIFY STATEMENT PLACEMENT. . . . . . . . . . . . . . . . 23 PROCESS IF STATEMENT. . . . . . . . . . . . . . . . . . . 24 PROCESS PROCEDURE STATEMENT . . . . . . . . . . . . . . . 25 PROCESS DO STATEMENT. . . . . . . . . . . . . . . . . . . 26 PROCESS END STATEMENT . . . . . . . . . . . . . . . . . . 27 PROCESS END OF STATEMENT. . . . . . . . . . . . . . . . . 28 DECLARATION PROCESSING . . . . . . . . . . . . . . . . . . . 29 PROCESS DECLARATION LIST. . . . . . . . . . . . . . . . . 30 SCAN DECLARATION LIST . . . . . . . . . . . . . . . . . . 31 SCAN DECLARATION ITEM . . . . . . . . . . . . . . . . . . 32 SCAN ATTRIBUTES . . . . . . . . . . . . . . . . . . . . . 33 INSTALL DECLARATION ITEMS . . . . . . . . . . . . . . . . 34 INSTALL BASIC ENTRY . . . . . . . . . . . . . . . . . . . 35 INSTALL STRUCTURE ENTRIES . . . . . . . . . . . . . . . . 36 INSTALL DECLARATION ATTRIBUTES. . . . . . . . . . . . . . 37 EXPRESSION AND REFERENCE PROCESSING. . . . . . . . . . . . . 38 PROCESS EXPRESSION. . . . . . . . . . . . . . . . . . . . 39 PROCESS OPERAND . . . . . . . . . . . . . . . . . . . . . 40 BUILD UNARY NODE. . . . . . . . . . . . . . . . . . . . . 41 BUILD TOP NODE. . . . . . . . . . . . . . . . . . . . . . 42 PROCESS REFERENCE . . . . . . . . . . . . . . . . . . . . 43 PROCESS BASIC REFERENCE . . . . . . . . . . . . . . . . . 44 FORM POSSIBLE <SR> NODE . . . . . . . . . . . . . . . . . 45 PROCESS SINGLE REFERENCE. . . . . . . . . . . . . . . . . 46
Figure 7. Sample of a segment reference tree
CFG, INC. LOCOMOTOR DATA REDUCTION SEGMENT REFERENCE TREES STOW ---- LN DEF SEGMENT -- --- ------- 1 4 STOW 2 11 SET DEFAULTS 3 35 FIND STARTING SECTOR 4 6 WRITE ON TAPE 5 38 CONVERT TO TANK ID 6 19 BUILD PROCESSED DATA ARRAY 7 24 INITIALIZE INPUT BUFFERS 8 31 GET POINTS 9 34 GET BATCH 10 36 READ DISK 11 32 MOVE AND COUNT POINTS 12 26 MOVE TO BUFFER 13 20 PROCESS A POINT 14 21 AVERAGE OVER POINTS 15 29 START LINE 16 28 PRINT POINTS IN BUFFER 17 22 MOVE GOOD POINTS TO WORK BUFFER 18 28 PRINT POINTS IN BUFFER 19 25 ADVANCE INPUT BUFFERS 20 31 GET POINTS 21 34 GET BATCH 22 36 READ DISK 23 32 MOVE AND COUNT POINTS 24 26 MOVE TO BUFFER 25 17 BUILD COMPRESSED DATA ARRAY 26 10 DISPLAY COMPRESSED POINTS 27 5 EXECUTE A COMMAND 28 6 WRITE ON TAPE 29 38 CONVERT TO TANK ID 30 19 BUILD PROCESSED DATA ARRAY 31 24 INITIALIZE INPUT BUFFERS 32 31 GET POINTS 33 34 GET BATCH 34 36 READ DISK 35 32 MOVE AND COUNT POINTS 36 26 MOVE TO BUFFER 37 20 PROCESS A POINT 38 21 AVERAGE OVER POINTS 39 29 START LINE 40 28 PRINT POINTS IN BUFFER 41 22 MOVE GOOD POINTS TO WORK BUFFER 42 28 PRINT POINTS IN BUFFER 43 25 ADVANCE INPUT BUFFERS 44 31 GET POINTS 45 34 GET BATCH 46 36 READ DISK 47 32 MOVE AND COUNT POINTS 48 26 MOVE TO BUFFER
Figure 8. Part of an Index to a design
CFG INC. AIL DEVELOPMENT WORKBOOK (20.90) INDEX TO GROUPS AND SEGMENTS 3 GP MAIN PHASE FLOW 8 SG MAKE SUCCESSOR EDGE 7:08 7:11 7:19 31 SG MAKE LOOP ENTRY BLOCKS 30:02 39 SG MARK LOOP MEMBERSHIP 37:13 32 SG MARK ONE LOOP ENTRY BLOCK 31:13 4 SG OPTIMIZE 54 SG PERFORM BACKWARD MOVEMENT 37:17 45 SG PERFORM LOCAL CSE ELIMINATION 44:01 36 SG PERFORM TRANSFORMATIONS 4:06 47 SG PROCESS ASSIGNMENT FOR CSE 45:07 51:10 52:16 48 SG PROCESS CALL FOR CSE 45:09 51:12 52:18 46 SG PROCESS COMPUTATIONAL TRIPLE FOR CSE 45:05 17 SG PROCESS FETCH INFORMATION 14:05 16:08 16:10 16:12 16:13 16:15 16:18 18 SG PROCESS STORE INFORMATION 16:06 56 SG REDUCE STRENGTH 37:18 65 SG REDUCE STRENGTH OF ONE TRIPLE 56:7 27 SG RESOLVE TENTATIVE BACK DOMINATORS 25:09 55 GP STRENGTH REDUCTION PART OF TRANSFORMATIONS SUBPHASE 22 SG TRACE CALLS 4:03 23 SG TRACE ONE NODE
Figure 9. General Form of IF Construct
IF condition one or more statements ELSEIF condition one or more statements . . . ELSE one or more statements ENDIF
Figure 10. Example of DO CASE Construct
DO CASE of transaction type add: create initial record delete: IF deletion is authorized create deletion record ELSE issue error message ENDIF change: increment change count create change record other: issue error message ENDDO